알고 있어야 하는 내용 )
- 컬럼명 사이에 공백이 포함된 경우 ` ` 로 컬럼명을 묶어주어야 한다.
- floor() : 소수점 첫째자리에서 버림을 해주는 버림함수이다.
- limit : 결과값의 개수를 제한해준다.
- sum(1) : 일반적인 sum 함수와는 다르다. 모든 행에 1을 적용해 더해진 값을 알려준다.
- count(*) : 테이블에서의 행의 수를 직접적으로 집계해준다. 전체 몇개에 데이터가 있는지 !
필요 데이터 :
데이터 모두 classicmodels.dataset2
상품의 소분류 ➜ Department Name
리뷰의 평점 ➜ Rating
나이 ➜ Age
조회방법
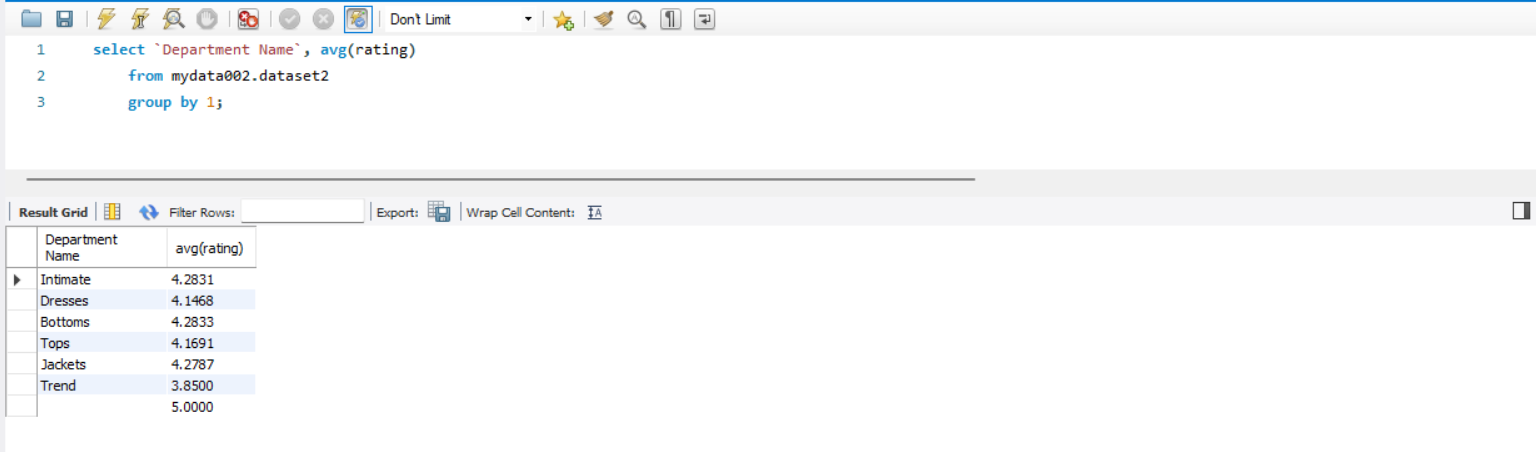
1. 상품의 소분류 별로 평점의 평균을 조회해보자
해석
상품의 소분류인 Department Name 컬럼명에는 공백이 포함되어있기 때문에 ` ` 안에 묶어주어야한다.
소분류 별로 조회해야하기 때문에 `Department Name` 으로 group by 를 이용해 그룹화를 해준다.
rating 의 평균을 구하기 위해 avg() 집계함수를 사용한다.
결과
상품의 소분류인 Trend 인 데이터의 평점이 낮은 것으로 판단된다.
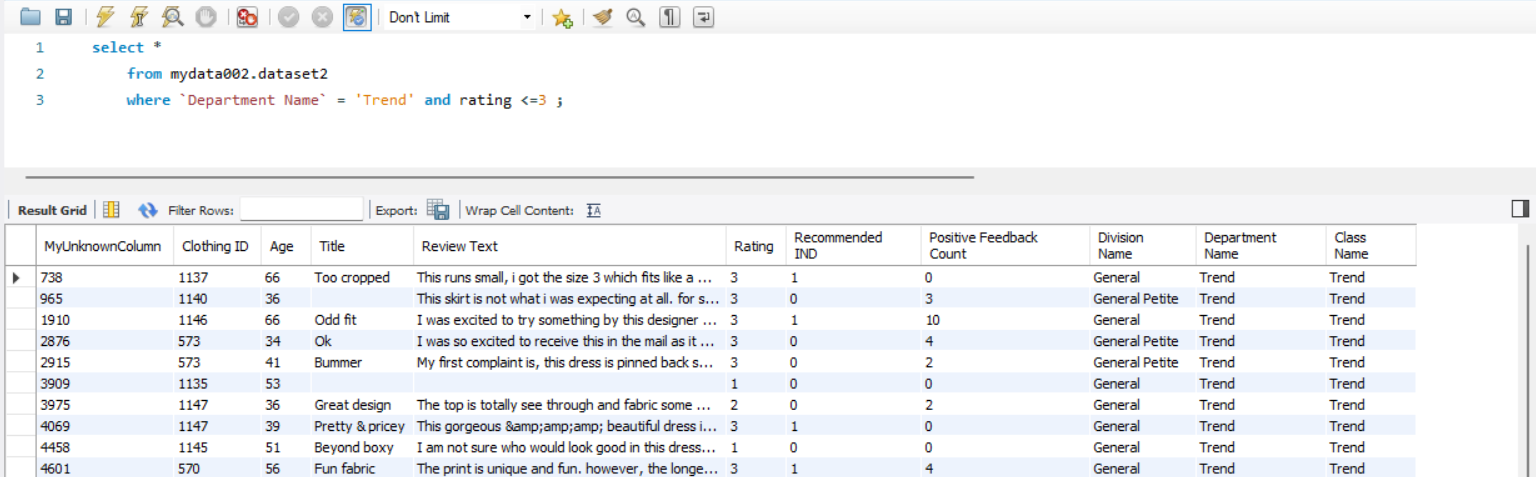
2. `Department Name` 이 Trend 인 데이터 중에 평점이 3점 이하인 데이터를 조회해보자
해석
where 조건절을 이용해서 조회 !
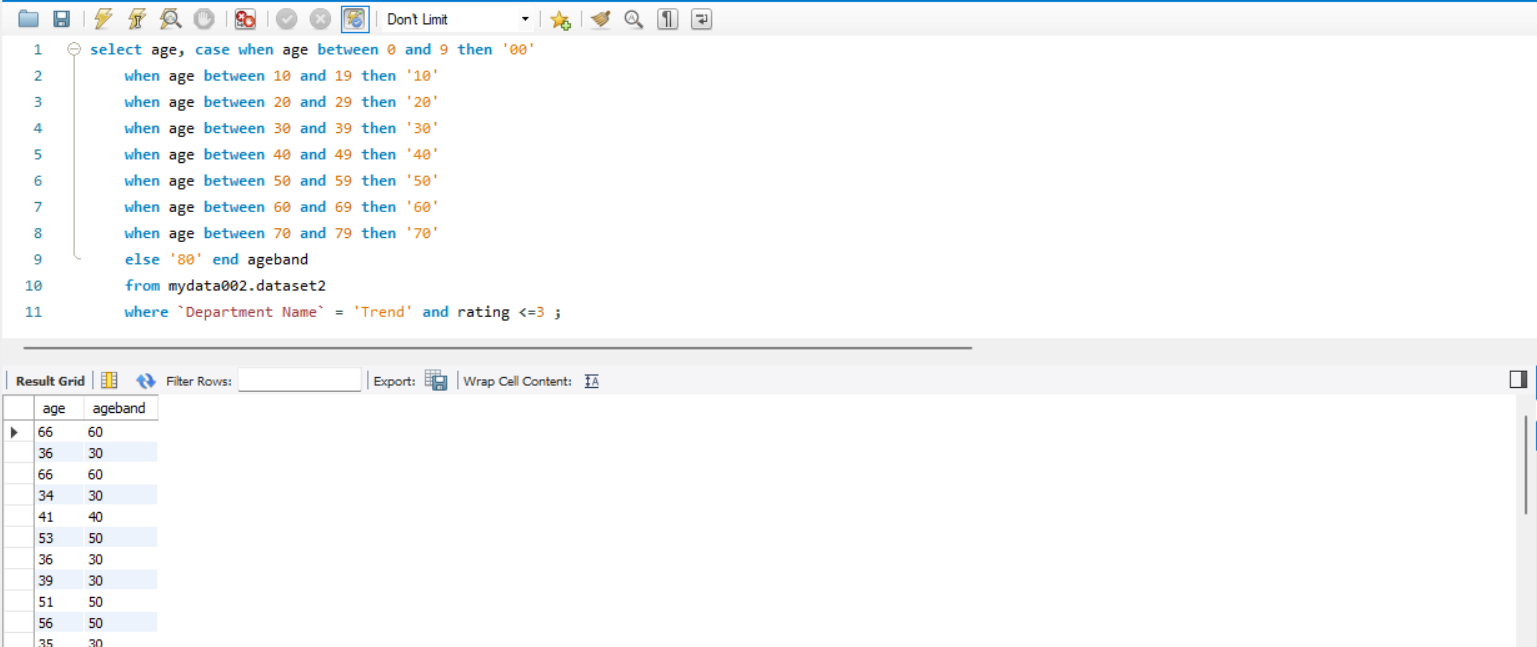
3-1. (2) 번의 데이터를 연령대별로 분류해보자 (case-when문)
해석
case when 문을 이용하여
0~9 : 00
10~19 : 10
20~29 : 20
30~39 : 30
40~49 : 40
50~59 : 50
60~69 : 60
70~79 : 70
80~ : 80
와 같이 연령대별로 분류해주었다.
이때 연령대의 컬럼명은 ageband 로 변경해주었다.
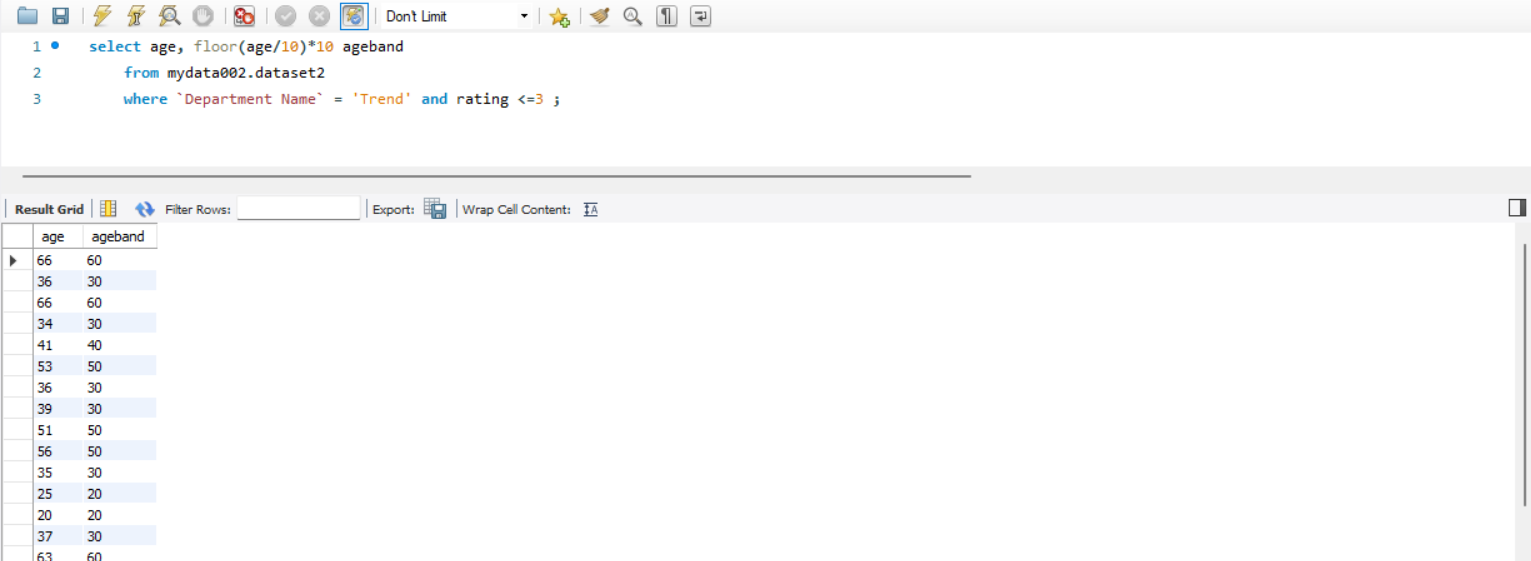
3-2 . (2) 번의 데이터를 연령대별로 분류해보자 (버림함수)
해석
floor() 함수는 소수점 첫째자리에서 버림해주는 함수이다.
floor() 함수를 사용하여 연령대별로 분류하면 case-when 문으로 작성하는 것보다 간결하게 작성할 수 있다.
4. (3) 번의 내용, Trend의 평점이 3점 이하인 리뷰의 연령분포를 테이블화 해주기
테이블명 : ct_001
해석
연령대별 분포를 알기 위해
연령대별로 그룹화를 해주고 count(*) 를 사용하여 몇개의 데이터가 있는데 행의 합을 구해주면 된다.
그리고 ct_001 의 이름으로 테이블화 해준다.
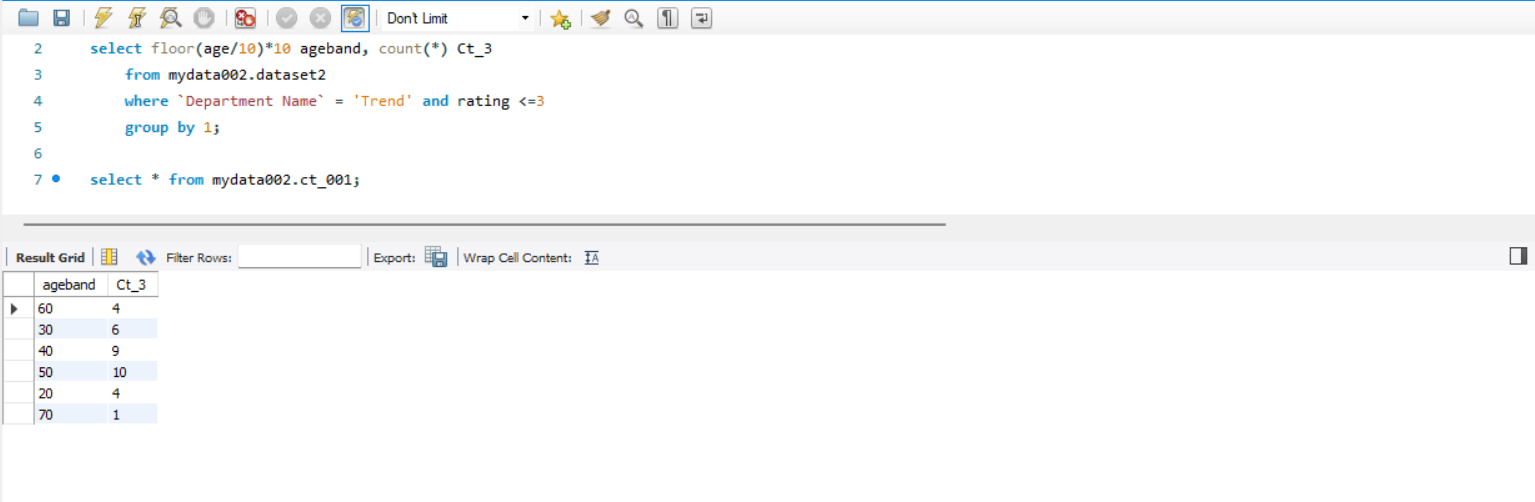
이때 거의 모든 30대가 낮은 평점을 준다고 단정지을 수 없다. 왜냐하면 10000명 중에 29명이 준 거일 수도 있고 29명 중에 29명이 준 거일 수도 있기 때문이다.
따라서 비율로 확인을 해야한다.
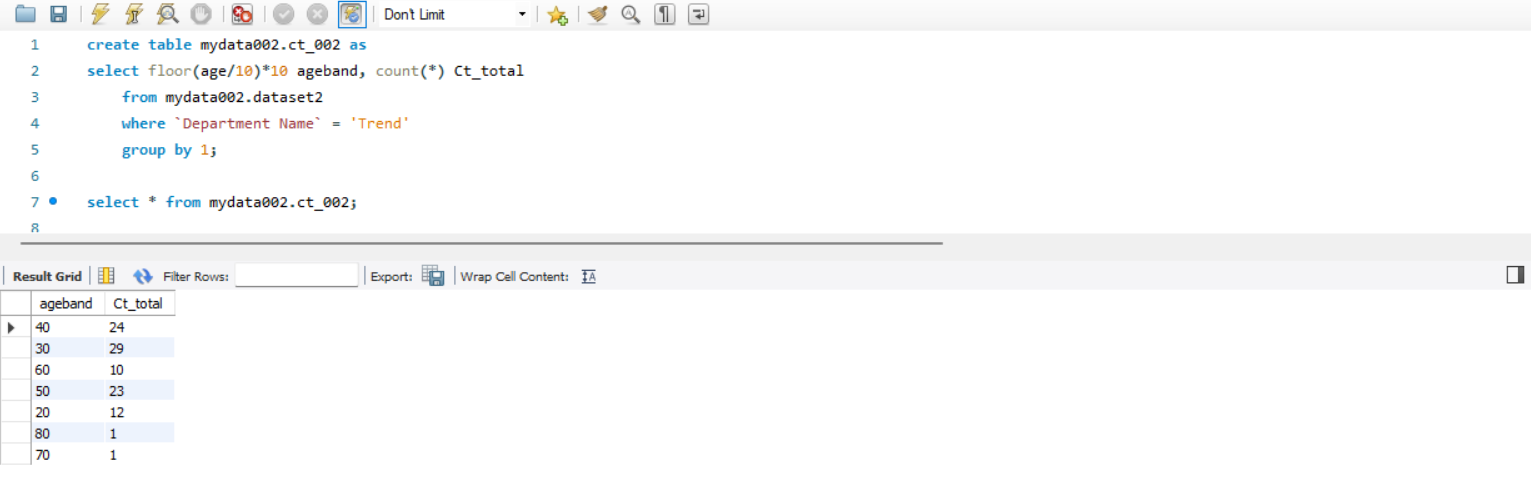
5. 비율을 구하기 위해 Trend 를 구매한 모든고객의 연령대별 분포를 조회하고 테이블화 해주기
테이블명 : ct_002
해석
(4) 번 내용에서 where 조건절만 수정해주면 된다.
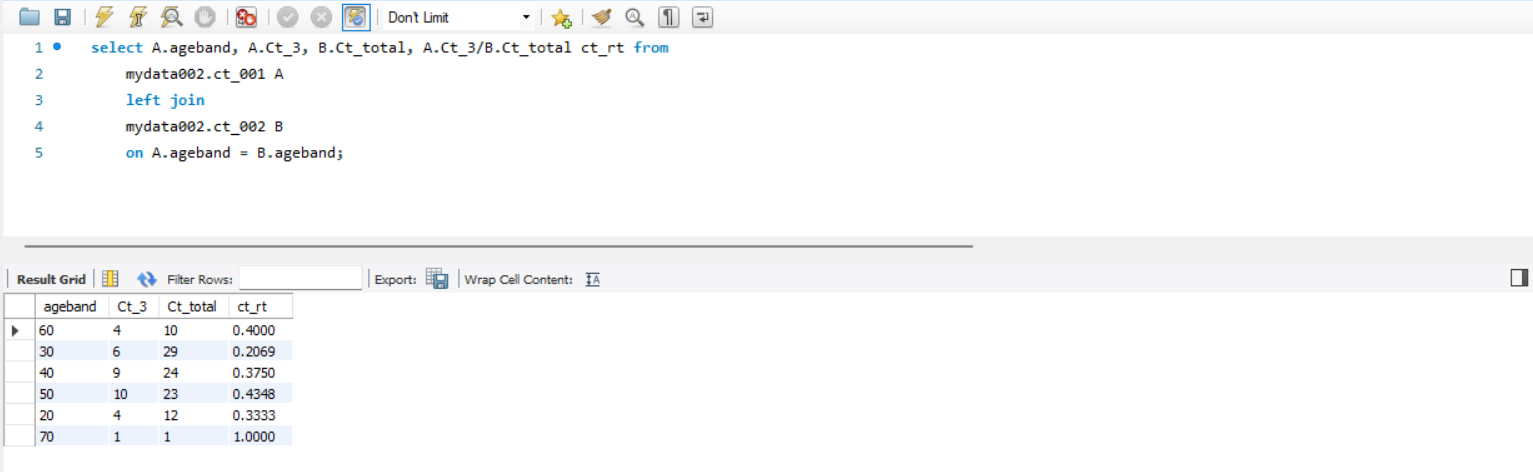
6. (4), (5) 의 내용으로 리뷰 비율을 조회해보자
해석
비율을 구하기 위해 ( 3점만 준 사람 수 / 전체 수 ) 를 구해준다.
그리고 컬럼명은 ct_rt 로 변경해준다.
결과
Trend 를 구매한 사람 중 50대가 가장 평점을 낮게 준 것으로 판단된다.
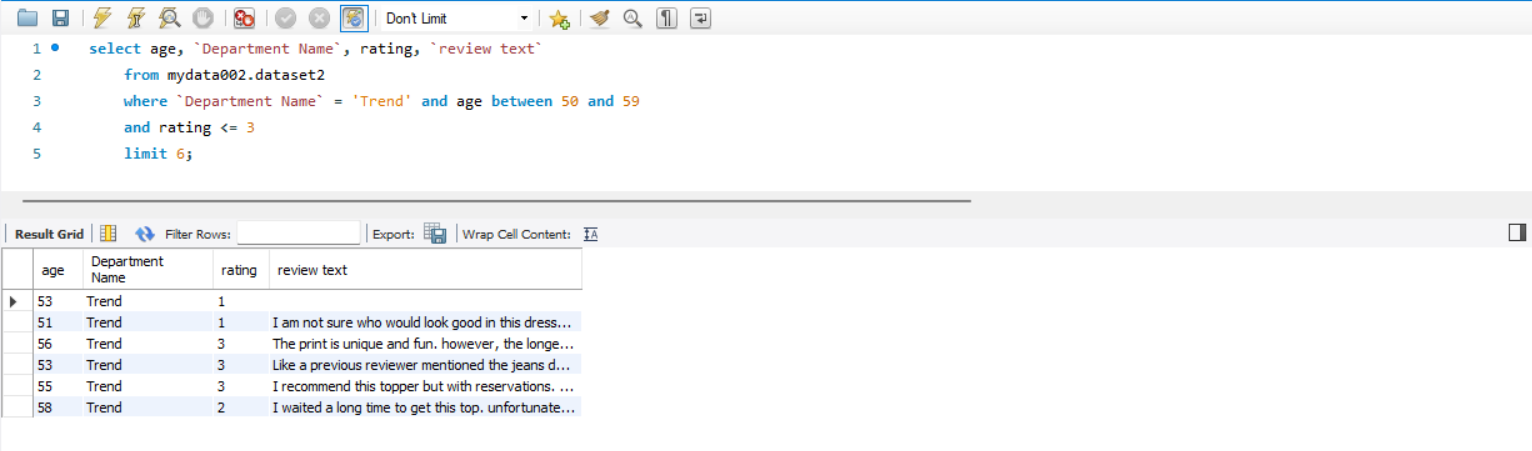
7. Trend 를 구매한 50대 중, 평점을 3점 이하로 준 고객의 리뷰를 조회해보자
이때, 상위 6개만 출력해라
해석
where 절에 조건을 넣어주고
상위 6개만 출력하기 위해 limit 6 을 사용한다.
'DATABASE' 카테고리의 다른 글
| Q. 카테고리가 'Bottoms' 인 데이터 중 평점이 낮은 상품의 리뷰 조회 (0) | 2023.11.25 |
|---|---|
| Q. 카테고리 별 평점이 낮은 주요 5개의 상품 조회 (0) | 2023.11.24 |
| 리뷰 테이블 dataset2 데이터 (0) | 2023.11.23 |
| Q. 활동고객이 많이 구매하는 제품의 계열 조회하기 (4) | 2023.11.22 |
| Q. 활동고객과 비활동고객 파악하기 (0) | 2023.11.18 |



